14 - Tokenization
Many NLP tasks make use of intensive matrix calculations, for which word id’s are used, rather than words. For this, raw text is split up into tokens that represent (sub)words.

Tokenization is the task of splitting raw text into smaller fundamental units; word tokens. This task is required for almost any NLP task. The goal is to build a vocabulary of word types (in spaCy: lexemes). A word type is a distinct word, in the abstract, rather than a specific instance. Word types are word tokens with no context. A word token is a word (string) observed in a piece of text.
How large your vocabulary should be, is a trade-off between memory limitations vs. coverage of word tokens. Each word token is converted to a unique id per word type. This is for performance reasons, because many NLP tasks make use of intensive (matrix) calculations.
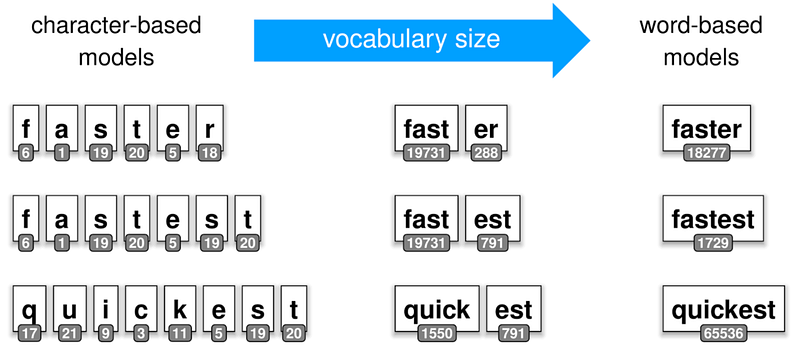
The text is generally split up into tokens that match words. But the text can also be split up into subwords or characters. The level of tokenization (or granularity) depends on the NLP-task and the target size for the total number of tokens for your vocabulary. The larger the vocabulary size the more common words you can tokenize and the more memory you need. The smaller the vocabulary size the more subword tokens you need to avoid having to use the -UNK- token (unknown).
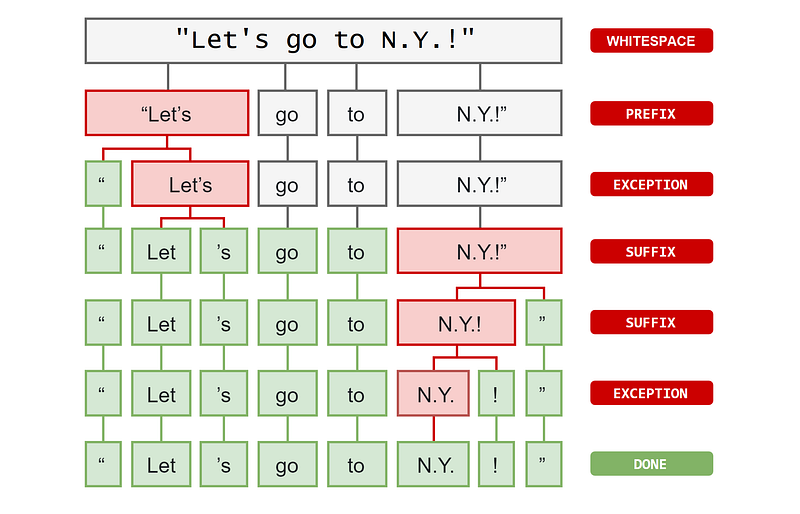
Above is an example of a word-level tokenizer. Techniques for subword tokenization are often used for training deeplearning models and have names like Wordpiece, Unigram and Byte Pair Encoding (BPE). For example, BPE ensures that the most common words will be represented in the new vocabulary as a single token, while less common words will be broken down into two or more subword tokens. More details here.
Once you choose a tokenizer and train a model on the tokenized data, you should always use that same tokenizer when using the model!
This article is part of the project Periodic Table of NLP Tasks. Click to read more about the making of the Periodic Table and the project to systemize NLP tasks.