22 - Spell Checker
Spell Checkers can recommend corrections on the word level.
Spell Checkers can recommend corrections on three levels: subword level, word level and sentence level. Spell Checkers evolved from rule-based to deeplearning models. Spark-NLP has a contextual spell checker model and spaCy has a contextual spell checker and a spellchecker based on Hunspell, which is the spell checker of Chrome, Firefox and OpenOffice.
Words that should not be corrected, can sometimes be defined as exceptions. This can be done with exception-classes and might have a high overlap with Named Entities. For example, the string ‘Aug-69’ is from the class Date and should not be corrected.
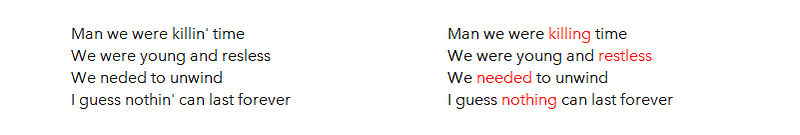
Spelling correction (but also Lemmatization, Stemming and Normalization) helps you decrease the unique number of tokens in your vocabulary, which improves performance in NLP tasks. Especially when you have noisy textual data like tweets.
An interesting application of Spell Checking is in OCR. The quality of extracted text from OCR can be improved by checking whether there are low-probability words or out-of-context words or out-of-vocabulary words that need to be corrected.
This article is part of the project Periodic Table of NLP Tasks. Click to read more about the making of the Periodic Table and the project to systemize NLP tasks.