34 - Text Anonymizer
Removing sensitive information before a document is shared with others. Deidentification and obfuscation of persons and organizations relies on Named Entity Recognition.
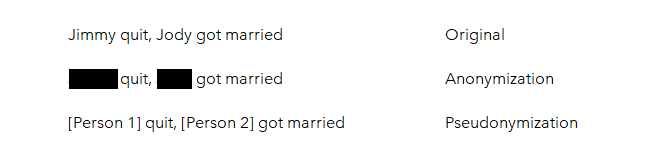
Text Anonymizing is the task of removing sensitive information before a document is shared with others. Deidentification and obfuscation is often done for strings that identify persons (name, social number, email, etc.) and organizations or for other sensitive details from crime records and patient dossiers.
A simple solution is to do Named Entity Recognition and replace the found mention with a tag. If it is Anonymization you replace the mention with nothing (the black marker). For Pseudonymization you replace the mention with a unique tag.
Text Anonymization has its use cases within governments and organizations that want to avoid being too transparent and have to deal with legal frameworks such as the General Data Protection Regulation (GDPR).
This article is part of the project Periodic Table of NLP Tasks. Click to read more about the making of the Periodic Table and the project to systemize NLP tasks.