62 - Contextualized Word Representations
Word Representations with the ability to incorporate context.

Contextualized / Dynamic Word Representations can be seen as incorporating context into word embeddings and is the ‘upgrade’ of Static Word Representations. Contextualized Embeddings can be found in models like BERT, ELMo, and GPT-2.
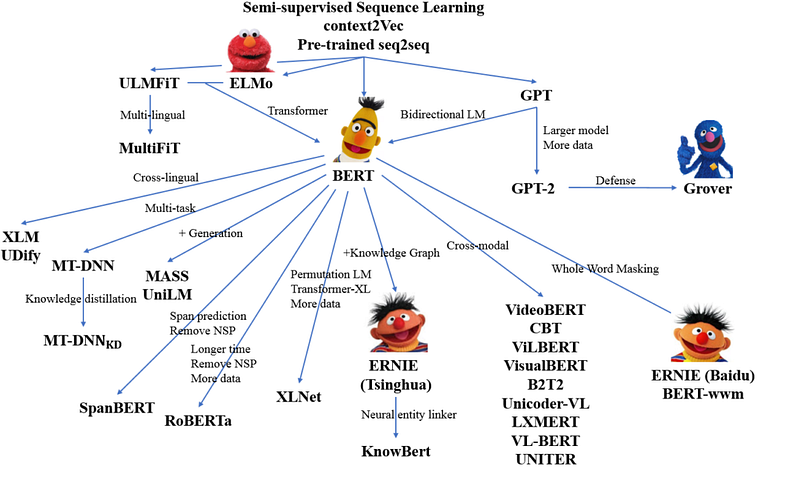
ELMo (Embeddings from Language Models by AllenNLP) was the response to the polysemy-problem and took context into consideration an LSTM-based model; same words having different meanings based on their context.
BERT (Bidirectional Encoder Representations from Transformers by Google) was a follow-up that considered the context from both the left and the right sides of each word. It was universal, because no domain-specific dataset was needed. It was also generalizable, because a pre-trained BERT model can be fine-tuned easily for various downstream NLP tasks.
GPT (Generative Pretrained Transformer by OpenAI) also emphasized the importance of the Transformer framework, which has a simpler architecture and can train faster and facilitates more parallelization than an LSTM-based model. It is also able to learn complex patterns in the data by using the Attention mechanism. Attention is an added layer that let’s a model focus on what’s important in a long input sequence.
For a technical summary of the (20+) available model types see this Transformers Summary from Huggin Face.
This article is part of the project Periodic Table of NLP Tasks. Click to read more about the making of the Periodic Table and the project to systemize NLP tasks.