Natural Language Models45 - Explaining ModelsExplaining the outcomes of your Language Model is needed to prevent distrust and increase transparency.
Natural Language Models44 - Evaluating ModelsEvaluating the quality of a Language Model should be done by comparisons based on the right metrics for your model type.
Natural Language Models43 - Training ModelsTraining Language Models should start with a simple baseline and be improved with more complex techniques.
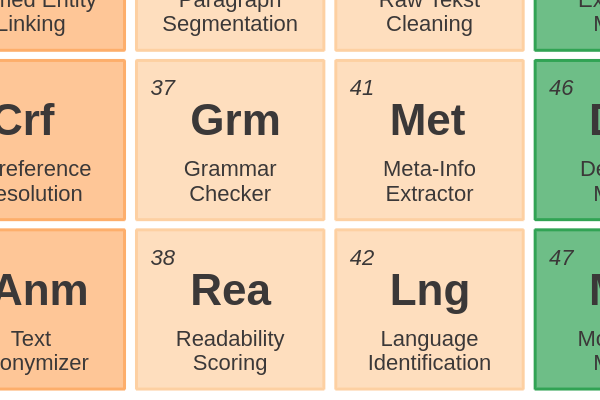
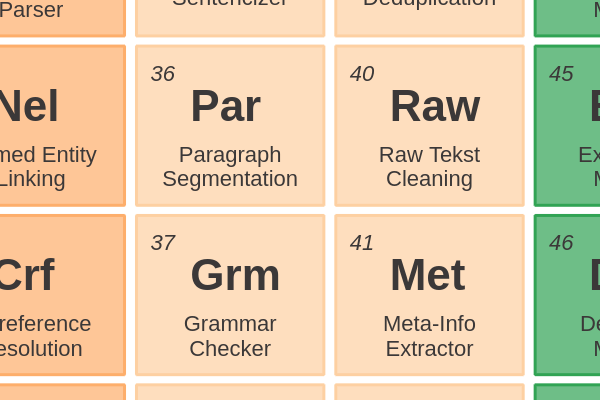
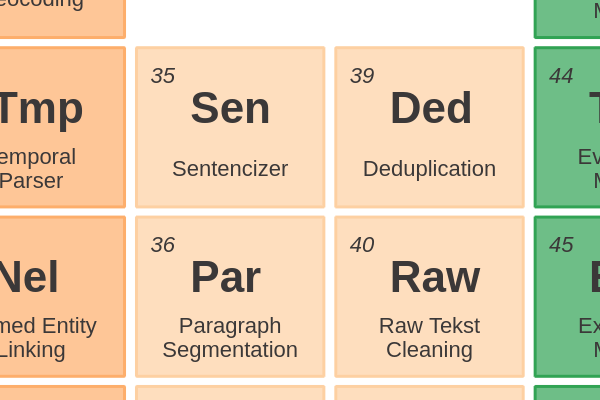
Documents42 - Language IdentificationIdentifying the language of a text is often done before you select the right language model.
Documents41 - Meta-Info ExtractorExtracting text from a file should be accompanied with the extraction of meta-information.
Documents40 - Raw Text CleaningPre-processing text with the goal to increase the quality of subsequent NLP tasks.
Documents39 - DeduplicationFinding texts that are exactly the same or show a high similarity. Similarity can be measured on lexicality or semantic meaning from embeddings.
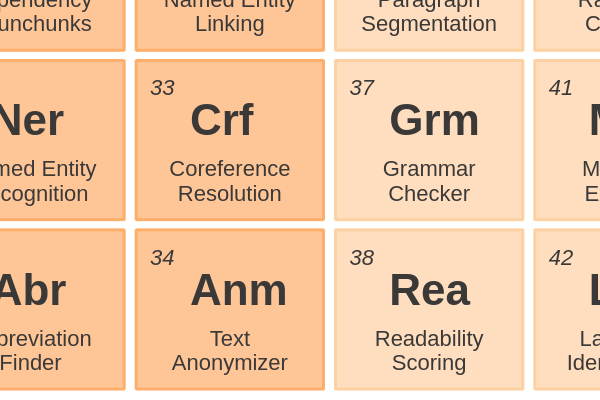
Sentences and Paragraphs38 - Readability ScoringMeasuring the readability of a text by looking at the keyword density, syllable count and the average length of sentences and words in a document.
Sentences and Paragraphs36 - Paragraph SegmentationSplitting text into paragraphs requires more custom logic. A paragraph might contain a more comprehensive meaning than a sentence.
Sentences and Paragraphs35 - SentencizerFinding the words that together form a sentence, or from another viewpoint, detecting sentence boundaries.
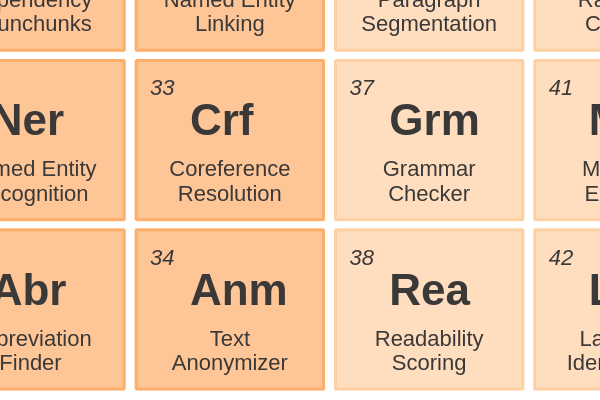
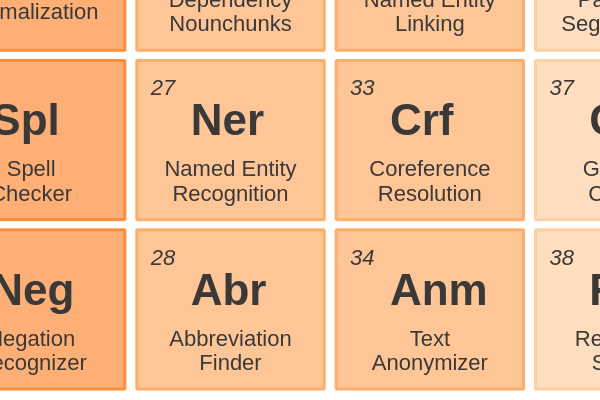
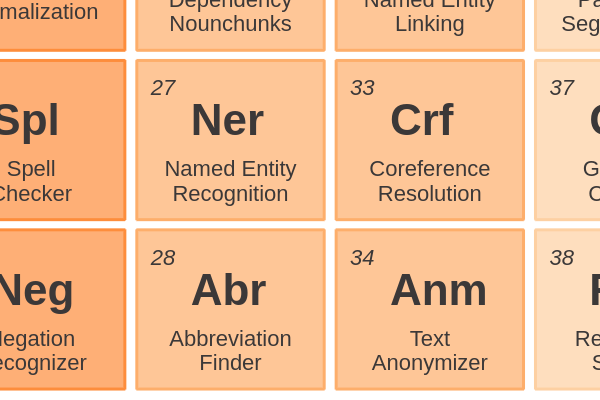
Entity Enriching34 - Text AnonymizerRemoving sensitive information before a document is shared with others. Deidentification and obfuscation of persons and organizations relies on Named Entity Recognition.
Entity Enriching33 - Coreference ResolutionFinding all expressions that refer to the same entity in a text. You can compare this to Named Entity Linking, but it doesn’t necessarily use a knowledge base.
Entity Enriching32 - Named Entity LinkingAssigning a unique identity from a knowledge base to a named entity.
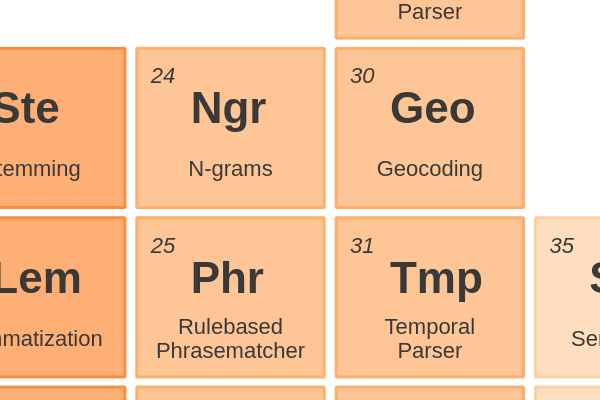
Entity Enriching31 - Temporal ParserFinding strings that contains an indication of time and then extracting a normalized time format out of it.
Entity Enriching30 - GeocodingParsing text into an address and converting an addresses into geographic coordinates like latitude and longitude.
Entity Enriching29 - Price ParserExtracting price and currency from raw text and normalize it into a standard format.
Phrases and Entities28 - Abbreviation FinderAbbreviations are an efficient way of writing, but it lowers text comprehension. To solve this, identify the long-form to enrich the short-form.
Phrases and Entities27 - Named Entity RecognitionIdentifying named entities is the task of assigning a NER category, like Persons, Locations or Organizations, to words in a sentence.
Phrases and Entities26 - Dependency NounchunksBreaking text into verb- or noun-phrases result into semantically correct subphrases of a sentence that are deducted from the dependency structure.
Phrases and Entities25 - Rulebased PhrasematcherFinite size lookup tables might inspire your to build rulebased searches, especially when semantic info like lemma’s and POS- and Dependency tags can be used in the search pattern.
Phrases and Entities24 - N-gramsDetecting N-grams results in common multi-word expression with a high probability of occurrence, like the Bi-gram ‘red wine’.